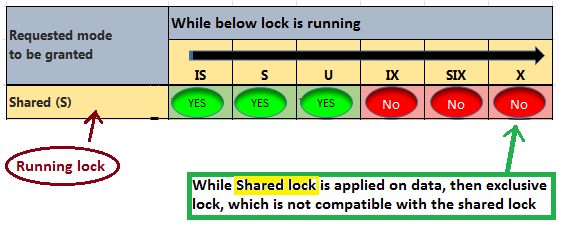
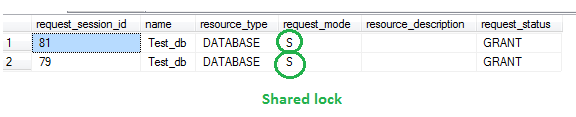
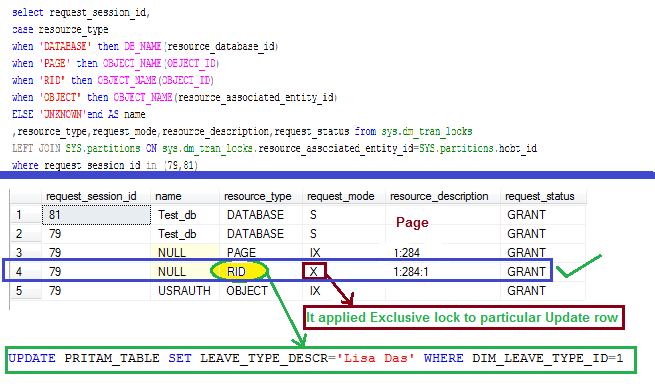
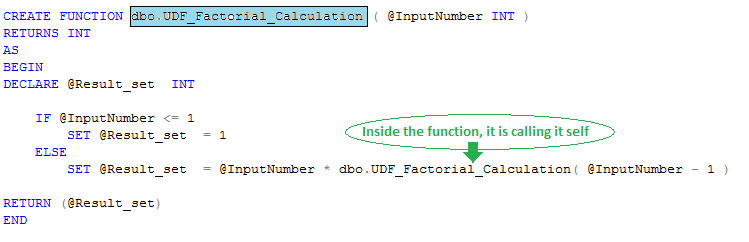
To understand Surrogate key concept we need to have clear picture on OLTP database and OLAP data Database.
In Data Warehouse (OLAP), there are 2 types of table (Dimension and Fact). By default we set a primary key on each dimension Table. This primary key column is the same primary key column (Business Key) form OLTP database table.
This is not recommended to be used as primary key in dimension table because of following reason mentioned below.
1. In OLTP database the the datatype of primary key column will be Unique-identifier or Alphanumeric character.
which consumes lot of indexes space when used as primary key. Since index size big, it makes data pooling slower.
2. In MNC business (Multiple Data source system) when we pool the data from various different source, there will be chance to lose control over record identifiers.(Same Primary value cumming from 2 different sources for 2 different objects)
3. SCD Implementation is not possible.(Historical data)
A surrogate key is a primary key, also having name meaningless key. We are using this key because, it is small and so efficient to store. To join dimension table and fact table using only surrogate key is recomanded, not business key.
Why surrogate key required ?
1. Surrogate keys are generally small integer numbers, which makes index size smaller when used as index column. This gives better performance due small index size.
2. We can tell something about the record just by looking at this key.
3. Historical versions of same data can be evaluate.
Implementation :
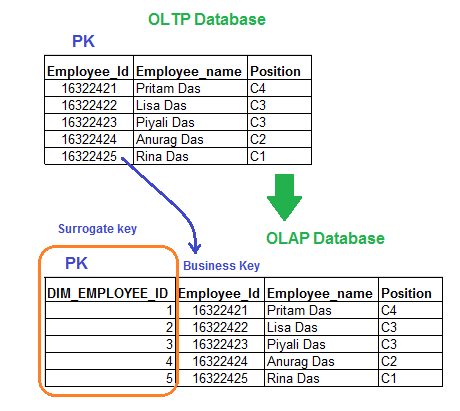
In Data Warehouse (OLAP), there are 2 types of table (Dimension and Fact). By default we set a primary key on each dimension Table. This primary key column is the same primary key column (Business Key) form OLTP database table.
This is not recommended to be used as primary key in dimension table because of following reason mentioned below.
1. In OLTP database the the datatype of primary key column will be Unique-identifier or Alphanumeric character.
which consumes lot of indexes space when used as primary key. Since index size big, it makes data pooling slower.
2. In MNC business (Multiple Data source system) when we pool the data from various different source, there will be chance to lose control over record identifiers.(Same Primary value cumming from 2 different sources for 2 different objects)
3. SCD Implementation is not possible.(Historical data)
A surrogate key is a primary key, also having name meaningless key. We are using this key because, it is small and so efficient to store. To join dimension table and fact table using only surrogate key is recomanded, not business key.
Why surrogate key required ?
1. Surrogate keys are generally small integer numbers, which makes index size smaller when used as index column. This gives better performance due small index size.
2. We can tell something about the record just by looking at this key.
3. Historical versions of same data can be evaluate.
Implementation :